How to Clone a Voice (Open-Source)
Here is the video: https://youtu.be/3fg7Ht0DSnE?si=gyqIdakpKI0Qf1Fy
What the junk is this?#
- This is the 3rd video in my Home Assistant series. This video picks up where I left off (and where I failed) in my last video attempting to replace Alexa with my own, fully local, AI voice assistant.
- I did everything but create a custom AI voice, specifically the voice of Terry Crews.
- In this video, I FINALLY figured out a consistent way to clone a voice from pretty much any source. But it has to be LOCAL and FREE.
You can clone my voice#
- I am giving you permission to clone my voice…but not for commercial purposes or for content creation. You are only allowed to use my voice as your personal voice assistant.
- If you would like to clone my voice, here is the voice dataset: https://drive.google.com/drive/folders/1i6mWm8z2K_3rtanrVn1UcNgw5LQ0Zyv6?usp=sharing
What Do You Need?#
…just a computer. But if you have a GPU….better.
Here is what I am using and demonstrating in this video:
- Laptop with an Nvidia 3080 GPU
- Terry (my AI PC that I built in this video —> https://youtu.be/Wjrdr0NU4Sk?si=_zlFoZq5g3jAcntA) rocking dual Nvidia 4090s
- A cloud GPU (AWS EC2 instance)
- I used a g5.12xlarge instance (4 GPUs)
Step 1 - Data Prep#
- The key to any AI project is getting CLEAN DATA. Let’s do that now.
- For this tutorial, I’m going to show you two options:
- Record your voice using the Piper Recording Studio
- Pull audio data from YouTube videos
the Piper Recording Studio#
This option is for you if you want to clone your own voice (or someone close to you) and you are willing to sit still for an hour while saying nonsensical phrases to a computer. (Kind of what I do for a living.)
What do you need?#
- This will be VERY Linux-based, so you will need Mac, Linux or WSL2 running on Windows.
- In my demonstration, I’m showing you how to very quickly setup WSL2. (If you have no idea what WSL is but would like to know more….check out this video —-> https://youtu.be/vxTW22y8zV8?si=FpeB_ZiwrOweGZW_)
Quick WSL2 Setup#
wsl --install Ubuntu-22.04
## Why Ubuntu 22.04? It was the most stable in my testing.
Get some things setup#
(Linux and WSL2)
## Update repos
sudo apt update
## Clone the Piper Recording Studio repo from GitHub
git clone https://github.com/rhasspy/piper-recording-studio.git
## Jump into the directory
cd piper-recording-studio
## Create a Python Virtual Environment
python3 -m venv .venv
## Activate that Python Virtual Environment
source .venv/bin/activate
## Upgrade PIP
python3 -m pip install --upgrade pip
## Install requirements for this project
python3 -m pip install -r requirements.txt
## Now RUN the Piper Recording Studio
python3 -m piper_recording_studio
## Hit CTRL-C when you are done.
Record some stuff#
- Navigate to http://localhost:8000 to access the Web Interface of the Piper Recording Studio and start recording your lovely voice.
Prepare the stuff you recorded#
## Jump into the directory where your recordings live
cd output/en_US/nameofyourrecordingstuff.chat
## Install ffmpeg
sudo apt install ffmpeg
## Jump back to the piper_recording_studo directory and export your data
cd ../../
python3 -m export_dataset ~/path/to/your/recorded/files ~/your/output/directory
## Deactivate your virtual environment
deactivate
YouTube Videos#
Download YouTube Videos#
## Make a new directory for this data prep and jump in there
mkdir dataprep
cd dataprep
## Create a new python virtual environment and activate it
python3 -m venv .venv
source .venv/bin/activate
## Install YT-DLP to download YouTube Videos
pip install yt-dlp
## Download the audio from a YouTube video
yt-dlp -x --audio-format wav "youtube URL"
Cleanup your audio samples#
- Piper TTS will want audio samples between 5-15sec. Any larger and it will hate you.
Use Audacity to trim clips..etc#
- Audacity (free and open-source audio tool): https://www.audacityteam.org/
- When exporting with Audacity (or any other program) Piper is wanting the audio in this format:
- !
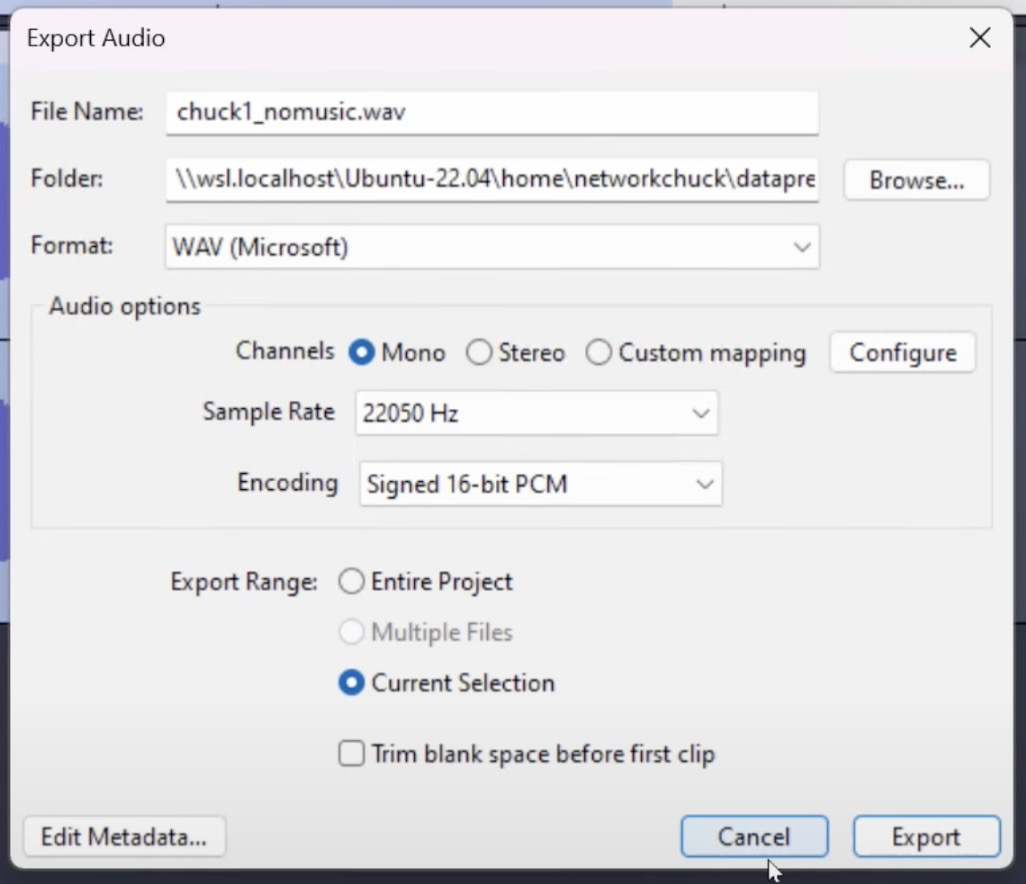
- Sample Rate: 22050 Hz
- Encoding: Signed 16-bit PCM
- Channels: mono
- Format: wav
- !
Remove Silence#
for file in ./*.wav; do
ffmpeg -i "$file" -af "silenceremove=stop_periods=-1:stop_duration=3:stop_threshold=-20dB" "./${file%.wav}_nosilence.wav"
done
Cut up your files#
## Create another directory
mkdir wav
## Cut it up
for file in *.wav; do
ffmpeg -i "$file" -f segment -segment_time 15 -c copy "./wav/split_${file%.*}_%03d.wav"
done
Get your samples ready for Piper TTS#
Transcribe your audio samples with Whisper#
Install Whisper#
pip install git+https://github.com/openai/whisper.git
Create a new python script and run it#
nano whispersomethingtome.py
Paste this script
import os
import whisper
# Initialize Whisper model (you can choose between 'tiny', 'base', 'small', 'medium', 'large')
model = whisper.load_model("base")
# Path to the directory containing the audio files
audio_dir = "./wav"
output_csv = "./metadata.csv"
# List all .wav files in the directory
audio_files = [f for f in os.listdir(audio_dir) if f.endswith(".wav")]
audio_files.sort() # Sort the files alphabetically (optional)
# Open the CSV file for writing
with open(output_csv, "w") as f:
for audio_file in audio_files:
# Full path to the audio file
audio_path = os.path.join(audio_dir, audio_file)
# Transcribe the audio file
result = model.transcribe(audio_path)
# Extract the transcription text
transcription = result["text"].strip()
# Write the filename (without .wav extension) and transcription to the CSV
file_id = os.path.splitext(audio_file)[0] # Get file name without extension
f.write(f"{file_id}|{transcription}\n")
print(f"Transcriptions complete! Metadata saved to {output_csv}")
Run the script
python3 whispersomethingtome.py
Clean it up
## Deactivate your python virtual environment
deactivate
## Go back home
cd ~/
Prepare to Train (Piper Recording Studio and YouTube)#
Prep Your Training Environment#
## Make a new directory for training
mkdir training
cd training
## Clone the Piper Repo
git clone https://github.com/rhasspy/piper.git
## Create another python virtual environment and activate it
python3 -m venv .venv
source .venv/bin/activate
Solving your headaches#
Because Piper TTS is picky
## Install a VERY specific version of PIP
python3 -m pip install pip==23.3.1
## Install a VERY specific version of numpy
pip install numpy==1.24.4
## Install a VERY specific version of torchmetrics
pip install torchmetrics==0.11.4
More prep#
## Jump into the Piper directory
cd piper/src/python
## If you have a 4090...this will save you ---> https://github.com/rhasspy/piper/issues/295
## Setup wheel
python3 -m pip install --upgrade wheel setuptools
## Install requirements
pip3 install -e .
## Run this script (I don't know what it does...but piper needs it)
./build_monotonic_align.sh
Make Piper LOVE your data#
## This will process your dataset, getting it ready for Piper to train
python3 -m piper_train.preprocess \
--language en \
--input-dir ~/your_training_data_directory/ \
--output-dir ~/your_output_directory \
--dataset-format ljspeech \
--single-speaker \
--sample-rate 22050
Download a starting point#
- You DON’T want to start training from scratch. We will download a pre-trained model that already has a headstart.
- Download High, Medium, or Low…depending on what you want —> https://huggingface.co/datasets/rhasspy/piper-checkpoints/tree/main/en/en_US/lessac
## Downloading the Lessac (medium) checkpoint
wget https://huggingface.co/datasets/rhasspy/piper-checkpoints/resolve/main/en/en_US/lessac/medium/epoch%3D2164-step%3D1355540.ckpt
Step 2 - Time to TRAIN!!!#
- Picking up from step 1, we are going to copy and paste this command.
python3 -m piper_train \
--dataset-dir ~/your_training_data_directory \
--accelerator 'gpu' \
--gpus 1 \
--batch-size 32 \
--validation-split 0.0 \
--num-test-examples 0 \
--max_epochs 6000 \
--resume_from_checkpoint "/place/where/you/downloaded/thecheckpoint/epoch=2218-step=838782.ckpt" \
--checkpoint-epochs 1 \
--precision 16 \
--max-phoneme-ids 400 \
--quality medium
- If you have DUAL GPUs, this script has a few fun things
python3 -m piper_train \
--dataset-dir ~/new_chuck/train-me \
--accelerator 'gpu' \
--gpus 2 \
--batch-size 32 \
--validation-split 0.0 \
--num-test-examples 0 \
--max_epochs 6000 \
--resume_from_checkpoint "/home/networkchuck/piper_project/base_checkpoints/high/epoch=2218-step=838782.ckpt" \
--checkpoint-epochs 1 \
--precision 16 \
--max-phoneme-ids 400 \
--quality high \
--strategy ddp
Stoping and Resuming#
- You can interrupt training and pickup where you left off.
- Just hit ctrl-c
- When you are ready to resume training, run the same command but change the checkpoint file to YOUR most recent checkpoint file. You would have seen this in the output of your training process.
!
When your final epoch is reached#
- It’s time to export your voice when training is done. Also know that you can export your voice at ANY point in training by simply targeting the most recent checkpoint file.
## Export the model
python3 -m piper_train.export_onnx \
"/path/to/your/checkpoint/checkpoints/epoch=5999-step=853906.ckpt" \
~/output/directory/voicename.onnx
## Copy the training json file to your model file directory
cp ~/training_directory/config.json ~/output/directory/voicename.onnx.json
Let’s test#
## Make sure you have Piper TTS installed
pip install piper-tts
## Test your voice
echo "Subscribe to NetworkChuck" | piper -m voicename.onnx --output_file test.wav
Read other posts